架起自然語(yǔ)言與視覺(jué)之間的橋梁一直是計(jì)算機(jī)視覺(jué)和多媒體領(lǐng)域追求的目標(biāo)��。這一領(lǐng)域早起探索的任務(wù)是對(duì)圖片進(jìn)行描述���,也就是生成單個(gè)句子描述圖片內(nèi)容�。近年來(lái)的工作則更多關(guān)注于對(duì)圖片和短視頻內(nèi)容進(jìn)行更為詳盡的描述��,生成包含多個(gè)句子的段落�����。同時(shí)�,研究者們也探索了根據(jù)照片流來(lái)講述故事。
不過(guò)����,人們?cè)谟涗浫松兄匾氖录r(shí),相比于短的視頻片段�����,往往更喜歡使用長(zhǎng)視頻��,比如生日派對(duì)和婚禮���。為此���,來(lái)自新加坡國(guó)立大學(xué)與明尼蘇達(dá)大學(xué)的研究者們提出了該領(lǐng)域新的任務(wù):針對(duì)長(zhǎng)視頻生成簡(jiǎn)介、連貫的描述性故事�。為此,他們建立了新的數(shù)據(jù)集并提出了新的模型�。在該數(shù)據(jù)集上,他們將新模型與前人工作中效果最佳的模型進(jìn)行了比較���,新模型取得了更優(yōu)的結(jié)果����。


圖|上圖為人類所寫(xiě)的故事; 下圖為新模型生成的故事����; 均只選擇了故事的前五句和視頻中它們nm相應(yīng)的關(guān)鍵幀的采樣。
針對(duì)長(zhǎng)視頻生成故事這一新任務(wù)與以往的各項(xiàng)任務(wù)都存在著顯著的差別��。與短視頻詳細(xì)描述任務(wù)相比��,該任務(wù)更關(guān)注包含復(fù)雜動(dòng)態(tài)事件的長(zhǎng)視頻�����,抽取其中的重要場(chǎng)景生成故事���,而不要求包含視頻中出現(xiàn)的每一個(gè)細(xì)節(jié)����。而與根據(jù)照片流生成故事相比��,該任務(wù)更基于視覺(jué)內(nèi)容���。因?yàn)橛烧掌魃晒适碌娜蝿?wù)中�,視覺(jué)材料由一張張照片組成,相對(duì)貧乏�,故而任務(wù)的關(guān)鍵是填補(bǔ)照片中間的信息鴻溝。這就意味著故事講述的過(guò)程需要想象力和先驗(yàn)知識(shí)��,得到的故事可能因?yàn)闃?biāo)注者的背景不同而產(chǎn)生很大差異����。而這項(xiàng)任務(wù)的視覺(jué)信息十分充足����,根據(jù)視覺(jué)信息就足以生成故事,不會(huì)受到過(guò)多主觀因素的影響��。
基于這些特性��,這項(xiàng)新任務(wù)也主要面臨兩大挑戰(zhàn)�。第一,與單句描述相比��,長(zhǎng)故事包含數(shù)量更多�,更多樣化的句子。而對(duì)于相同的視覺(jué)內(nèi)容�����,可能有多種多樣的描述。為此���,保證故事的簡(jiǎn)潔性和連續(xù)性就更為困難��。第二��,長(zhǎng)視頻中通常包含多個(gè)角色��、地點(diǎn)和活動(dòng)�����,難以把握故事的主線��。
為了應(yīng)對(duì)這些挑戰(zhàn)�,研究者將該任務(wù)分解為兩個(gè)子任務(wù)�����。首先從長(zhǎng)視頻中挖掘重要的片段���,然后通過(guò)檢索的方式選擇合適的句子生成故事����。根據(jù)這兩個(gè)子任務(wù),他們提出了由兩個(gè)部分組成的模型�����。
模型的第一部分是上下文感知多模態(tài)嵌入學(xué)習(xí)框架�,通過(guò)兩個(gè)步驟,由局部到全局建立起多模態(tài)語(yǔ)意空間��,也就是將視頻內(nèi)容和自然語(yǔ)言映射到同一語(yǔ)意空間中�,將其聯(lián)系在一起����。它首先對(duì)視頻片段-句子對(duì)進(jìn)行建模,然后將長(zhǎng)視頻轉(zhuǎn)化為一系列的視頻片段����。通過(guò)一個(gè)殘差雙向 RNN(Residual Bidirectional RNN)進(jìn)行處理。該結(jié)構(gòu)不僅能將上下文信息整合到多模態(tài)語(yǔ)意空間中����,同時(shí)可以保證時(shí)序上的連貫性和語(yǔ)意嵌入的多樣性。
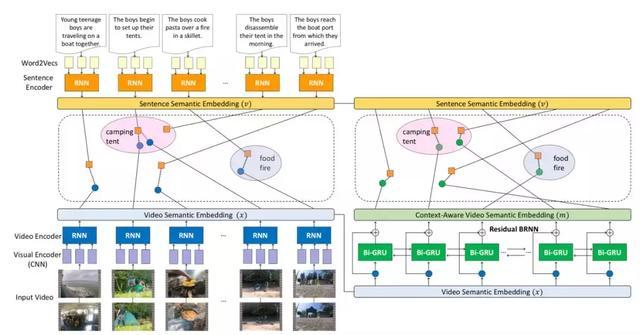
圖|局部到整體的多模態(tài)嵌入式學(xué)習(xí)模型����。左側(cè)部分為局部嵌入學(xué)習(xí)���。針對(duì)每一個(gè)輸入的視頻片段-句子對(duì),利用 CNN+RNN 對(duì)視頻片段進(jìn)行編碼���,利用 RNN 對(duì)句子進(jìn)行編碼����。
右側(cè)為全局嵌入學(xué)習(xí)����,將視頻片段和句子應(yīng)映射到同一語(yǔ)意空間。
模型的第二部分稱之為“旁白”����。給定一個(gè)視頻,該結(jié)構(gòu)首先從中抽取一系列重要的剪輯片段���,接下來(lái)在語(yǔ)意空間中檢索與這些剪輯片段最匹配的句子����,生成整個(gè)故事��。視頻中哪些方面對(duì)于一個(gè)好故事是重要的呢��?換句話說(shuō),什么樣的片段是重要的呢����?這顯然沒(méi)有一個(gè)明確的定義。因此�,這一模塊被設(shè)計(jì)為一個(gè)強(qiáng)化學(xué)習(xí)的代理,通過(guò)觀察一系列的輸入視頻來(lái)學(xué)習(xí)一個(gè)策略�,通過(guò)該策略選擇獎(jiǎng)勵(lì)最大的剪輯片段。而這個(gè)獎(jiǎng)勵(lì)���,就是通過(guò)這些剪輯片段生成的故事與人類書(shū)寫(xiě)的參考故事之間的相似度來(lái)決定。
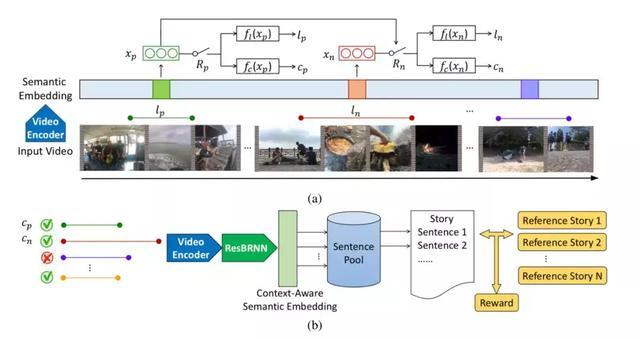
圖|上圖為旁白網(wǎng)絡(luò)���,根據(jù)輸入的視頻提取重要的視頻片段��。下圖為根據(jù)提取出的片段檢索出句子組合成故事的過(guò)程��。
數(shù)據(jù)集一直是驅(qū)動(dòng)該領(lǐng)域研究進(jìn)步的重要因素